为什么选择老张API?
老张API提供企业级AI技术API接入服务,解决开发者在使用多个AI模型时的支付门槛和接口统一问题。服务特色
OpenAI 兼容模式
老张API采用 OpenAI 兼容格式,统一接口调用200+AI模型: 支持的模型厂商:- 🤖 OpenAI:gpt-5.6、gpt-5.6-terra、gpt-5.6-luna、gpt-5.1-codex 等
- 🧠 Anthropic:claude-sonnet-5、claude-opus-4-8、claude-fable-5 等
- 💎 Google:gemini-3.6-flash、gemini-3.5-flash-lite、gemini-3.1-pro-preview 等
- 🚀 xAI:grok-4.5、grok-4.3、grok-4.20 系列等
- 🔍 DeepSeek:deepseek-v4-pro、deepseek-v4-flash 等
- 🌟 阿里:Qwen 系列模型
- 💬 Moonshot:Kimi 模型等
模型是否可调用取决于当前账号、令牌分组和线路。正式接入前请在控制台模型与价格页面确认准确模型 ID、实时价格和开放状态。
功能支持范围
✅ 支持的功能:- 💬 对话补全:Chat Completions接口
- 🖼️ 图像生成:gpt-image-2、flux-kontext-pro、flux-kontext-max 等
- 🔊 语音处理:Whisper转录
- 📊 嵌入向量:文本向量化
- ⚡ 函数调用:Function Calling
- 📡 流式输出:实时响应
- 🔧 OpenAI参数:temperature、top_p、max_tokens等
- 🆕 Responses端点:OpenAI最新功能
- 🔧 微调接口(Fine-tuning)
- 📁 Files管理接口
- 🏢 组织管理接口
- 💳 计费管理接口
简单切换模型
核心优势:一套代码,多种模型 用OpenAI格式跑通后,只要更换模型名称即可切换到其他大模型:快速开始 - API 技术接入
获取 API Key
- 访问 老张API控制台
- 登录您的账户
- 在令牌管理页面点击”新增”创建API Key
- 复制生成的API Key用于接口调用
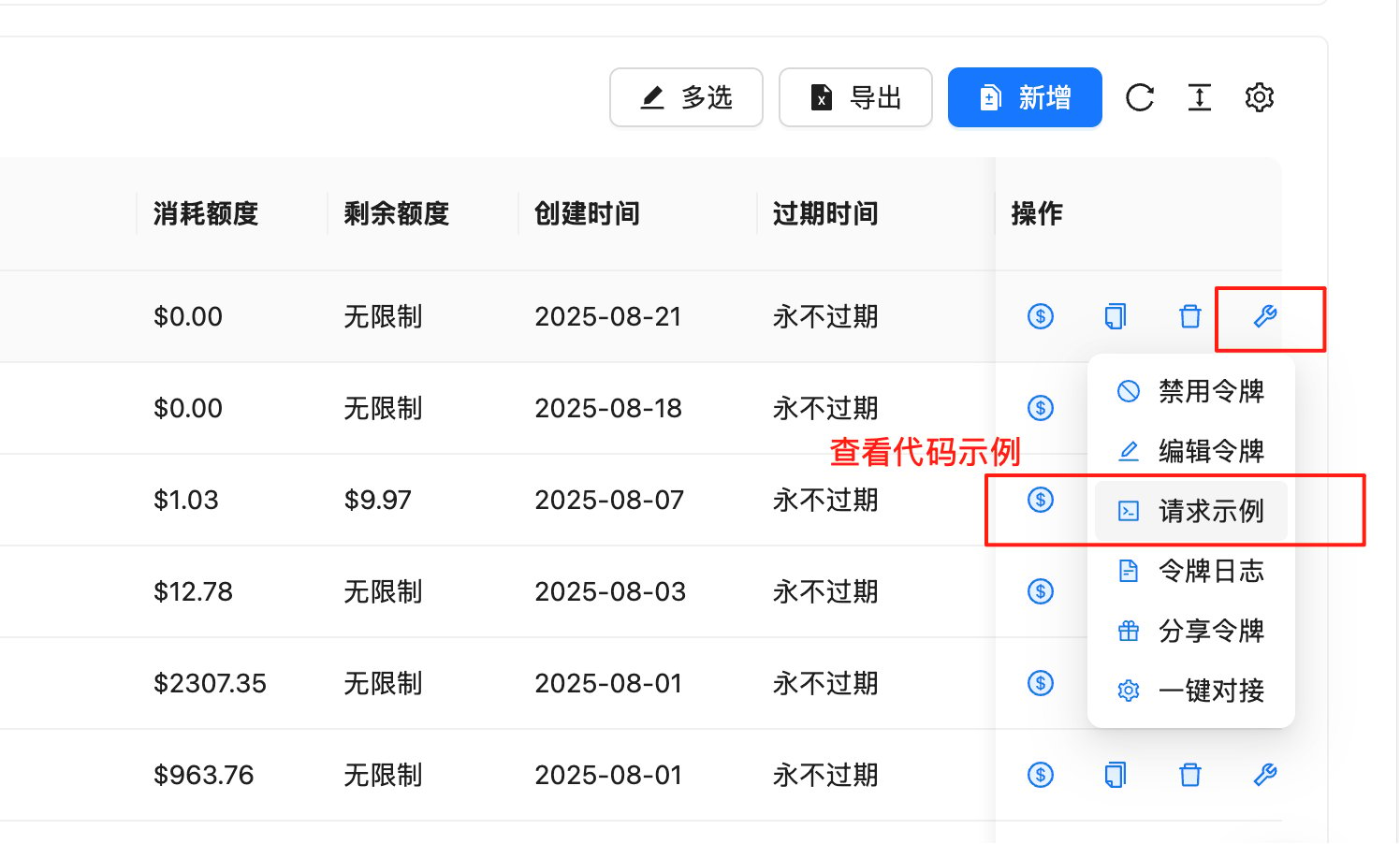
查看请求示例
在令牌管理页面,您可以快速获取各种编程语言的代码示例: 操作步骤:- 进入 令牌管理页面
- 找到您要使用的API Key所在的行
- 点击”操作”列中的🔧小扳手图标(工具图标)
- 在弹出菜单中选择”请求示例”
- 查看包含以下语言的完整代码示例:
- cURL - 命令行测试
- Python (SDK) - 使用官方OpenAI库
- Python (requests) - 使用requests库
- Node.js - JavaScript/TypeScript
- Java - Java应用开发
- C# - .NET应用开发
- Go - Go语言开发
- PHP - Web开发
- Ruby - Ruby应用开发
- 以及更多语言…
- ✅ 完整可运行:复制粘贴即可使用
- ✅ 参数说明:详细的参数配置
- ✅ 错误处理:包含异常处理逻辑
- ✅ 最佳实践:遵循各语言开发规范
建议开发者优先查看后台的请求示例,这些示例会根据最新的API版本实时更新,确保代码的准确性和可用性。
基础信息
API 端点
- 主要端点:
https://api2.laozhang.ai/v1(推荐,全球加速) - 备用端点:
https://api-vip.laozhang.ai/v1(海外服务器可直连)
api2.laozhang.ai 配置了全球加速的宽带节点,建议优先使用。api-vip.laozhang.ai 仅作为备用域名,适合海外服务器直连,如遇不稳定请切换回主域名。认证方式
所有 API 请求需要在 Header 中包含认证信息:请求格式
- Content-Type:
application/json - 编码格式:UTF-8
- 请求方法:POST(大部分接口)
核心接口
1. 对话补全(Chat Completions)
创建一个对话补全请求,支持多轮对话。 请求端点
消息格式
- cURL
- Python (SDK)
- Python (requests)
- Node.js
- Java
- C#
- Go
- PHP
- Ruby
2. 文本补全(Completions)
为兼容旧版接口保留,建议使用 Chat Completions。 请求端点3. 嵌入向量(Embeddings)
将文本转换为向量表示。 请求端点
完整代码示例
- cURL
- Python (SDK)
- Python (requests)
- Node.js
4. 图像生成(Images)
生成、编辑或变换图像。 生成图像推荐使用
gpt-image-2 模型进行图像生成。更多图像生成功能和参数说明,请查看 GPT图像生成详细文档。- cURL
- Python (SDK)
- Node.js
5. 音频转文字(Audio)
语音识别和转录。 转录音频6. 模型列表
获取可用模型列表。 请求端点流式响应
开启流式输出
在请求中设置stream: true:
流式响应格式
响应将以 Server-Sent Events (SSE) 格式返回:处理流式响应
- Python
- JavaScript
错误处理
错误响应格式
常见错误码
错误处理示例
最佳实践
1. 请求优化
- 合理设置 max_tokens:避免不必要的长输出
- 使用 temperature:控制输出的随机性
- 批量处理:合并多个请求减少调用次数
2. 错误重试
实现指数退避的重试机制:3. 安全建议
- 保护API密钥:使用环境变量存储
- 限制权限:为不同应用创建不同的密钥
- 监控使用:定期检查API使用日志
4. 性能优化
- 使用流式输出:提升用户体验
- 缓存响应:对相同请求缓存结果
- 并发控制:合理控制并发请求数
速率限制
RPM、TPM 和并发限制会随模型、令牌分组、线路和账户配置变化,不使用统一固定值。请在控制台确认当前限制,并以渐进方式提高生产流量。 超出当前限制时通常会返回 429。客户端应读取错误信息,采用指数退避并限制重试次数;不要在未确认模型可用性和账户额度前持续重试。需要帮助?
- 访问 老张API官网
- 查看 支持的模型
- 联系技术支持:hi@laozhang.ai
本手册持续更新中,请关注最新版本以获取新功能和改进。