Platform Introduction
Dify provides a complete AI application development platform, featuring:- 🎨 Visual Workflow Editor - Build complex AI applications via drag-and-drop
- 🔌 Multi-model Support - Support for OpenAI, Anthropic, Google and other providers
- 📝 Prompt Engineering - Built-in powerful prompt template system
- 💬 Conversation Management - Complete conversation history and context management
- 🔄 RAG Support - Integrated retrieval-augmented generation capability
- 🚀 Quick Deployment - Support for API and Web applications
- 📊 Data Analysis - Comprehensive application usage analysis
Quick Integration
Step 1: Log in to Dify Platform
Visit your Dify instance (self-hosted or cloud version), log in to your account.Step 2: Add Model Provider
Fill In Configuration
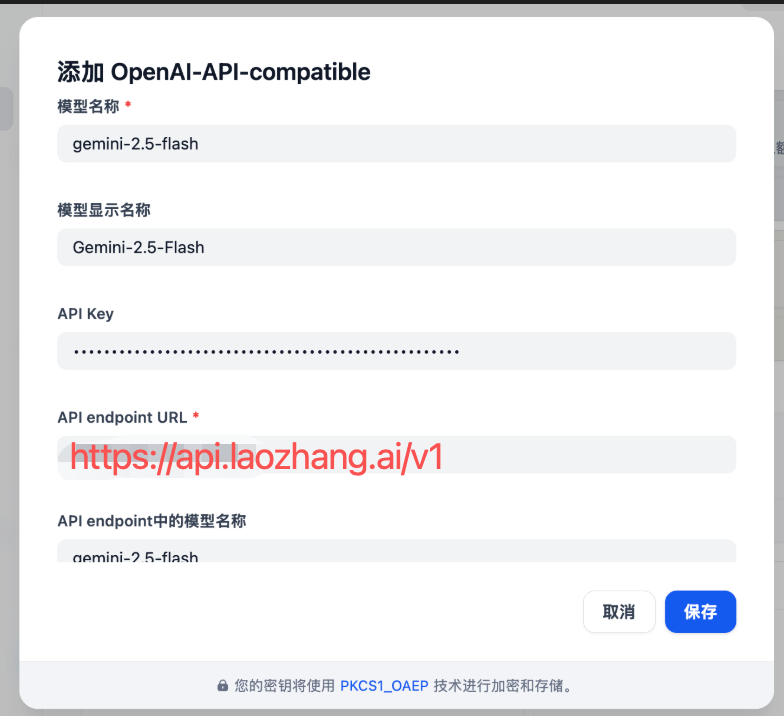
- Provider Name: Laozhang API (custom name)
- API Base URL:
https://api.laozhang.ai/v1 - API Key: Enter your Laozhang API key
- Model Type: Select models you need (completion/chat/embedding)
Obtaining API KeyVisit Laozhang API Console to create and obtain your API key.
Step 3: Select Model
- Creating new applications
- Configuring workflows
- Setting Agent models
Supported Models
Dify supports the following model types through Laozhang API:Text Generation Models (Chat/Completion)
| Model Series | Model ID | Features | Recommended Scenarios |
|---|---|---|---|
| GPT-4 Turbo | gpt-4-turbo | Powerful reasoning ability | Complex business logic, code generation |
| GPT-3.5 Turbo | gpt-3.5-turbo | Fast response, economical | Chatbots, quick queries |
| Claude Sonnet | claude-sonnet-4 | Long context support | Document processing, content creation |
| Gemini Pro | gemini-2.5-pro | Multimodal support | Image understanding, comprehensive analysis |
Embedding Models
| Model | Dimension | Features |
|---|---|---|
text-embedding-ada-002 | 1536 | High-quality semantic understanding |
text-embedding-3-small | 512 | Lightweight, fast |
text-embedding-3-large | 3072 | Highest precision |
Application Scenarios
1. Intelligent Customer Service Chatbot
Build an intelligent customer service system capable of:- 24/7 automated responses
- Multi-turn context conversation
- Knowledge base integration
- Intent recognition and routing
- Model:
gpt-3.5-turbo(economical and fast) - RAG: Enable knowledge base retrieval
- Temperature: 0.7
- Max Tokens: 1000
2. Document Analysis Assistant
Process and analyze large documents:- Automatic document summarization
- Key information extraction
- Q&A based on documents
- Multi-document comparison
- Model:
claude-sonnet-4(long context support) - RAG: Enable vector database
- Temperature: 0.3 (more accurate)
- Max Tokens: 2000
3. Code Generation Tool
Help developers write code:- Automatic code generation
- Code explanation and annotation
- Code review
- Bug fixing suggestions
- Model:
gpt-4-turbo(strong code capability) - Temperature: 0.2 (more deterministic)
- Max Tokens: 2000
4. Content Creation Platform
Assist in creating various content:- Article writing
- Marketing copy
- Product descriptions
- SEO optimization
- Model:
gpt-4-turboorclaude-sonnet-4 - Temperature: 0.8 (more creative)
- Max Tokens: 2000
Advanced Features
RAG (Retrieval Augmented Generation)
Integrate your private knowledge base:-
Create Knowledge Base
- Upload documents (PDF, Word, Markdown, etc.)
- Automatic chunking and vectorization
- Choose appropriate embedding model
-
Configure Retrieval Strategy
- Set retrieval quantity (Top K)
- Set similarity threshold
- Choose reranking strategy
-
Integration into Application
- Associate knowledge base in workflow
- Configure retrieval parameters
- Test retrieval effectiveness
Workflow Orchestration
Build complex AI workflows:Agent Capabilities
Create autonomous AI agents:- Tool Calling - Call external APIs
- Multi-step Reasoning - Decompose complex tasks
- Self-reflection - Evaluate and improve outputs
- Memory Management - Maintain long-term memory
API Integration
Dify provides comprehensive APIs to integrate your applications:Python Example
JavaScript Example
Streaming Response
Support streaming output for better user experience:Deployment Guide
Docker Deployment
Environment Variables
Troubleshooting
Connection Issues
Problem: Unable to connect to Laozhang API Solutions:- Check if API Base URL is correct:
https://api.laozhang.ai/v1 - Verify API Key validity
- Ensure network connection is normal
- Check firewall settings
Model Unavailable
Problem: Selected model cannot be used Solutions:- Verify model ID is correct
- Check account balance
- Confirm model is in service scope
- Try other models
RAG Performance Issues
Problem: Retrieval results are inaccurate Solutions:- Optimize document chunking strategy
- Adjust retrieval parameters (Top K, similarity threshold)
- Try different embedding models
- Add more relevant documents
High Latency
Problem: Response speed is slow Solutions:- Switch to a faster model (e.g., GPT-3.5 Turbo)
- Reduce Max Tokens setting
- Optimize prompt length
- Enable caching mechanism
Best Practices
1. Prompt Engineering
Write effective prompts:2. Cost Optimization
Control usage costs:- Use lighter models for simple tasks (GPT-3.5 Turbo)
- Set reasonable Max Tokens limits
- Enable result caching
- Batch process requests
- Regularly review usage
3. Security Configuration
Protect sensitive data:- Use environment variables to store API keys
- Enable API rate limiting
- Implement user authentication
- Audit logs
- Data encryption
4. Performance Optimization
Improve application performance:- Enable caching mechanism
- Use CDN to distribute static resources
- Optimize database queries
- Implement load balancing
- Monitor system performance