Nano Banana Standard 编辑:低成本 1K 图改图路线
- 稳定模型 ID:
gemini-2.5-flash-image - 老张API价格:当前 $0.025/次,实际价格与扣费以控制台为准
- 适用场景:背景替换、元素增删、风格转换和简单多图合成
- 高分辨率任务:2K/4K 请使用 Nano Banana Pro 图改图
控制台入口
创建 API Key,查看余额和调用日志
🚀 在线测试
影图 AI 即刻体验,无需写代码
不确定该用 Lite、Nano Banana 2、Pro 还是 Standard?先看 图像生成 API 选型指南。老张API使用统一全球 HTTPS 入口,适合高频生产接入;网关不设置固定低并发套餐档位,但最终容量仍受上游与账号状态影响。
模型简介
Nano Banana (Standard) 图像编辑功能基于 Googlegemini-2.5-flash-image 模型,通过对话补全接口实现对现有图片的智能编辑和改造。支持单张或多张图片的输入,可以实现图像合成、元素添加、风格转换等高级编辑功能。
🎨 智能图像编辑
上传图片 + 文字描述 = 精准编辑!支持多图合成、元素修改、风格转换等高级功能。
🌟 核心特性
- 🔄 灵活编辑:支持元素添加/删除、风格转换、图像合成等
- 🎭 多图处理:可同时处理多张图片,实现融合、拼接等效果
- 💰 价格以控制台为准:$0.025/次,按次计费,价格透明
- 🚀 快速处理:平均 10 秒完成编辑
- 📦 Base64 输出:直接返回编辑后的 base64 图片数据
📋 功能对比
| 功能 | Nano Banana 编辑 | Nano Banana Pro 编辑 | GPT-4o 编辑 | DALL·E 2 编辑 | Flux 编辑 |
|---|---|---|---|---|---|
| 价格 | $0.025/次 | $0.09/次 | Token计费 | $0.018/张 | $0.035/次 |
| 模型 | Gemini 2.5 | Gemini 3 Pro | GPT-4o | DALL·E 2 | Flux |
| 多图输入 | ✅ 支持 | ✅ 强 | ✅ 支持 | ❌ 不支持 | ❌ 原生不支持 |
| 响应速度 | ~10秒 | ~20秒 | 较慢 | 中等 | |
| 返回格式 | Base64 | Base64 | URL | URL | |
| 中文支持 | ✅ 完美 | ✅ 完美 | ❌ 需翻译 | ❌ 需翻译 |
🚀 快速开始
准备工作
1
创建令牌
登录 老张API令牌管理 创建按次计费类型的令牌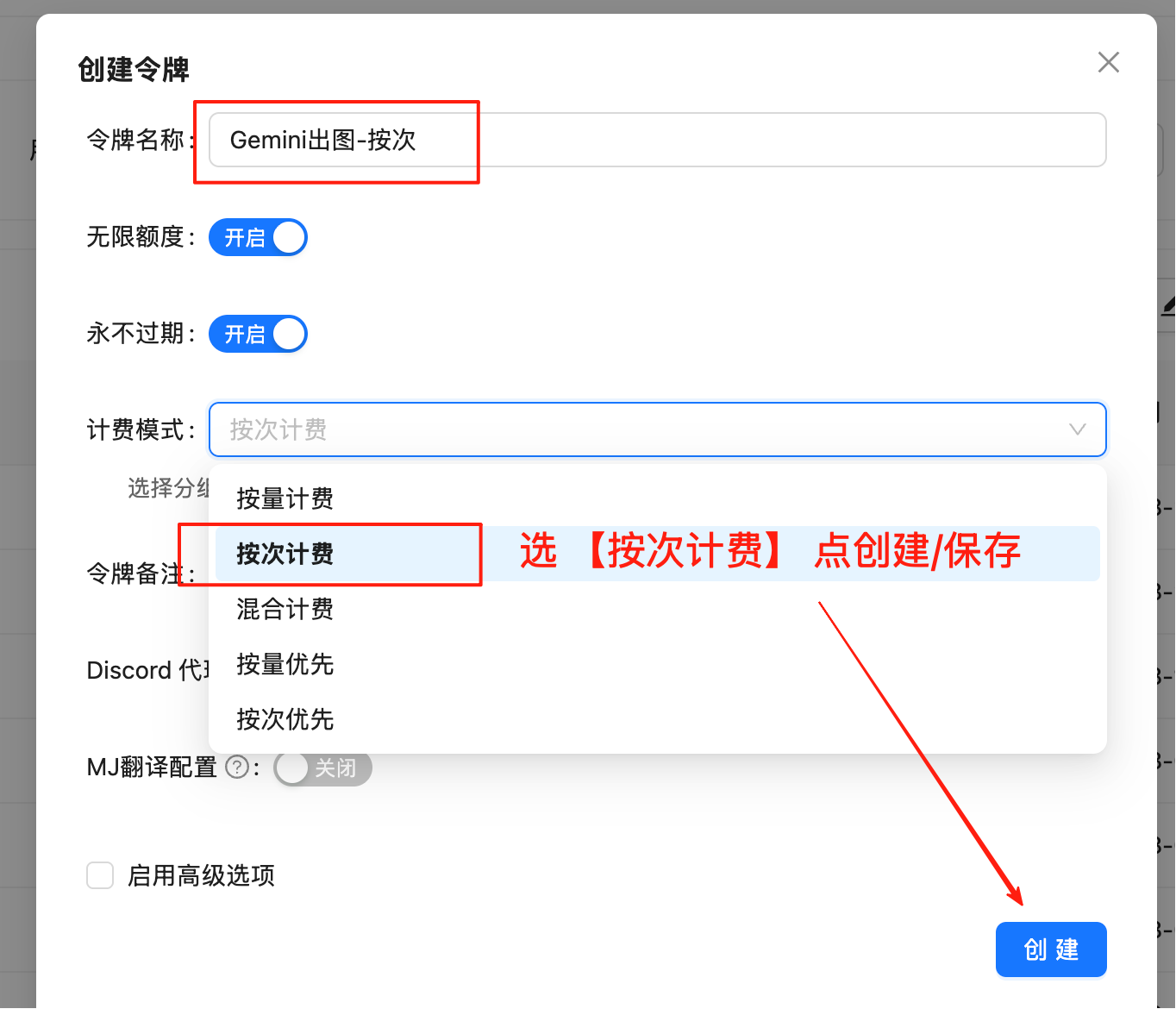
2
选择计费方式
重要:必须选择”按次计费”类型,不要选择”按量计费”
3
保存令牌
复制生成的令牌,格式为
sk-xxxxxx,在代码中替换 YOUR_API_KEY💰 价格说明
- 老张API:$0.025/次(价格以控制台为准)
- Google Standard 参考价:$0.039/次
- 扣费说明:按次计费,实际扣费可在调用日志中查看
基础示例 - 单图编辑
curl -X POST "https://api2.laozhang.ai/v1/chat/completions" \
-H "Authorization: Bearer sk-YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-2.5-flash-image",
"stream": false,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "add a dog to this image"
},
{
"type": "image_url",
"image_url": {
"url": "https://github.com/dianping/cat/raw/master/cat-home/src/main/webapp/images/logo/cat_logo03.png"
}
}
]
}
]
}'
Python 示例 - 多图合成
#!/usr/bin/env python3
import requests
import json
import base64
import re
from datetime import datetime
import sys
# 配置
API_KEY = "sk-YOUR_API_KEY" # 请替换为你的实际密钥(按次计费类型)
API_URL = "https://api2.laozhang.ai/v1/chat/completions"
def edit_images_with_gemini():
"""多图合成编辑示例"""
# 设置请求头
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 请求数据 - 支持多张图片输入
data = {
"model": "gemini-2.5-flash-image",
"stream": False,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Combine these 2 images creatively and add a Corgi dog"
},
{
"type": "image_url",
"image_url": {
"url": "https://github.com/dianping/cat/raw/master/cat-home/src/main/webapp/images/logo/cat_logo03.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/leonindy/camel/master/camel-admin/src/main/webapp/assets/images/camel_logo_blue.png"
}
}
]
}
]
}
print("正在请求API...")
try:
# 发送请求
response = requests.post(API_URL, headers=headers, json=data)
response.raise_for_status()
print("API请求成功,正在处理响应...")
# 解析响应
result = response.json()
# 提取内容
content = result['choices'][0]['message']['content']
print(f"收到内容: {content[:200]}...") # 显示前200个字符
# 查找Base64图片数据
# 方法1: 查找标准格式 data:image/type;base64,data
base64_match = re.search(r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)', content)
if base64_match:
base64_data = base64_match.group(1)
print("找到标准格式的Base64数据")
else:
# 方法2: 查找纯Base64数据(长字符串)
base64_match = re.search(r'([A-Za-z0-9+/=]{100,})', content)
if base64_match:
base64_data = base64_match.group(1)
print("找到纯Base64数据")
else:
print("错误: 无法找到Base64图片数据")
print("完整响应内容:")
print(json.dumps(result, indent=2, ensure_ascii=False))
return False
# 生成文件名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"edited_image_{timestamp}.png"
print("正在保存图片...")
# 解码并保存图片
try:
image_data = base64.b64decode(base64_data)
with open(filename, 'wb') as f:
f.write(image_data)
print(f"图片已成功保存为: {filename}")
print(f"文件大小: {len(image_data)} 字节")
return True
except Exception as e:
print(f"错误: 保存图片时出现问题: {e}")
return False
except requests.exceptions.RequestException as e:
print(f"错误: API请求失败: {e}")
return False
except KeyError as e:
print(f"错误: 响应格式不正确,缺少字段: {e}")
print("完整响应内容:")
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
return False
except Exception as e:
print(f"错误: 未知错误: {e}")
return False
if __name__ == "__main__":
success = edit_images_with_gemini()
sys.exit(0 if success else 1)
Bash 脚本 - 批量编辑
#!/bin/bash
# Nano Banana 图像编辑 - Bash版本
# 支持单图/多图编辑,自动保存base64结果
# 设置API密钥(请替换为你的实际【按次计费】的密钥)
API_KEY="sk-YOUR_API_KEY"
# 设置输出文件名
OUTPUT_FILE="edited_image_$(date +%Y%m%d_%H%M%S).png"
echo "正在请求API进行图像编辑..."
# 发送curl请求并保存响应到临时文件
RESPONSE=$(curl -s -X POST "https://api2.laozhang.ai/v1/chat/completions" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-2.5-flash-image",
"stream": false,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Combine 2 images and add a Corgi dog image"
},
{
"type": "image_url",
"image_url": {
"url": "https://github.com/dianping/cat/raw/master/cat-home/src/main/webapp/images/logo/cat_logo03.png"
}
},
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/leonindy/camel/master/camel-admin/src/main/webapp/assets/images/camel_logo_blue.png"
}
}
]
}
]
}')
# 检查请求是否成功
if [ $? -ne 0 ]; then
echo "错误: API请求失败"
exit 1
fi
echo "API请求成功,正在处理响应..."
# 从响应中提取Base64图片数据
BASE64_DATA=$(echo "$RESPONSE" | python3 -c "
import json
import sys
import re
try:
data = json.load(sys.stdin)
content = data['choices'][0]['message']['content']
# 查找Base64图片数据
base64_match = re.search(r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)', content)
if base64_match:
print(base64_match.group(1))
else:
# 尝试查找纯Base64数据
base64_match = re.search(r'([A-Za-z0-9+/=]{100,})', content)
if base64_match:
print(base64_match.group(1))
else:
print('ERROR: No Base64 data found')
sys.exit(1)
except Exception as e:
print(f'ERROR: {e}')
sys.exit(1)
")
# 检查是否成功提取Base64数据
if [[ "$BASE64_DATA" == ERROR* ]]; then
echo "$BASE64_DATA"
echo "完整响应内容:"
echo "$RESPONSE"
exit 1
fi
if [ -z "$BASE64_DATA" ]; then
echo "错误: 无法从响应中提取Base64图片数据"
echo "完整响应内容:"
echo "$RESPONSE"
exit 1
fi
echo "成功提取Base64数据,正在保存图片..."
# 将Base64数据解码并保存为图片文件
echo "$BASE64_DATA" | base64 -d > "$OUTPUT_FILE"
# 检查文件是否成功创建
if [ -f "$OUTPUT_FILE" ] && [ -s "$OUTPUT_FILE" ]; then
echo "图片已成功保存为: $OUTPUT_FILE"
echo "文件大小: $(ls -lh "$OUTPUT_FILE" | awk '{print $5}')"
else
echo "错误: 图片保存失败"
exit 1
fi
echo "✨ 编辑完成!"
🎯 编辑场景示例
1. 单图编辑 - 添加元素
def add_element_to_image(image_url, element_description):
"""向图片添加新元素"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "gemini-2.5-flash-image",
"stream": False,
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": f"Add {element_description} to this image"},
{"type": "image_url", "image_url": {"url": image_url}}
]
}]
}
response = requests.post(API_URL, headers=headers, json=data)
return extract_base64_from_response(response.json())
# 使用示例
result = add_element_to_image(
"https://example.com/landscape.jpg",
"a rainbow in the sky"
)
2. 多图合成 - 创意融合
def creative_merge(image_urls, merge_instruction):
"""创意合并多张图片"""
content = [{"type": "text", "text": merge_instruction}]
# 添加所有图片
for url in image_urls:
content.append({
"type": "image_url",
"image_url": {"url": url}
})
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "gemini-2.5-flash-image",
"stream": False,
"messages": [{
"role": "user",
"content": content
}]
}
response = requests.post(API_URL, headers=headers, json=data)
return extract_base64_from_response(response.json())
# 使用示例
images = [
"https://example.com/cat.jpg",
"https://example.com/background.jpg"
]
result = creative_merge(images, "将猫咪自然地融入到背景中")
3. 风格转换
def style_transfer(image_url, style_description):
"""图片风格转换"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": "gemini-2.5-flash-image",
"stream": False,
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": f"Transform this image into {style_description} style"},
{"type": "image_url", "image_url": {"url": image_url}}
]
}]
}
response = requests.post(API_URL, headers=headers, json=data)
return extract_base64_from_response(response.json())
# 使用示例
result = style_transfer(
"https://example.com/photo.jpg",
"Van Gogh painting"
)
4. 批量编辑处理
class BatchImageEditor:
"""批量图像编辑器"""
def __init__(self, api_key):
self.api_key = api_key
self.api_url = "https://api2.laozhang.ai/v1/chat/completions"
def process_batch(self, tasks):
"""
批量处理编辑任务
tasks: [(image_urls, instruction), ...]
"""
results = []
for i, (image_urls, instruction) in enumerate(tasks, 1):
print(f"处理任务 {i}/{len(tasks)}: {instruction[:50]}...")
try:
result = self.edit_images(image_urls, instruction)
results.append({
"task_id": i,
"instruction": instruction,
"success": True,
"output": result
})
print(f"✅ 任务 {i} 完成")
except Exception as e:
results.append({
"task_id": i,
"instruction": instruction,
"success": False,
"error": str(e)
})
print(f"❌ 任务 {i} 失败: {e}")
return results
def edit_images(self, image_urls, instruction):
"""编辑图片"""
if isinstance(image_urls, str):
image_urls = [image_urls]
content = [{"type": "text", "text": instruction}]
for url in image_urls:
content.append({
"type": "image_url",
"image_url": {"url": url}
})
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
data = {
"model": "gemini-2.5-flash-image",
"stream": False,
"messages": [{"role": "user", "content": content}]
}
response = requests.post(self.api_url, headers=headers, json=data)
response.raise_for_status()
return self.extract_and_save_base64(response.json())
def extract_and_save_base64(self, response_data):
"""提取并保存base64图片"""
content = response_data['choices'][0]['message']['content']
# 提取base64数据
base64_match = re.search(r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)', content)
if not base64_match:
base64_match = re.search(r'([A-Za-z0-9+/=]{100,})', content)
if base64_match:
base64_data = base64_match.group(1)
# 保存图片
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
filename = f"edited_{timestamp}.png"
image_data = base64.b64decode(base64_data)
with open(filename, 'wb') as f:
f.write(image_data)
return filename
else:
raise ValueError("未找到base64图片数据")
# 使用示例
editor = BatchImageEditor(API_KEY)
tasks = [
(["https://example.com/cat.jpg"], "给猫咪戴上帽子"),
(["https://example.com/room.jpg"], "将房间改为夜晚氛围"),
(["https://example.com/img1.jpg", "https://example.com/img2.jpg"], "创意融合两张图片")
]
results = editor.process_batch(tasks)
💡 最佳实践
1. 编辑指令优化
# ❌ 模糊指令
instruction = "edit the image"
# ✅ 清晰具体的指令
instruction = """
1. 在图片右上角添加一轮明月
2. 调整整体色调为暖色系
3. 增加一些萤火虫的光点效果
4. 保持原图的主体不变
"""
2. 多图处理策略
def smart_multi_image_edit(images, instruction):
"""智能多图编辑,自动处理不同数量的图片"""
if len(images) == 1:
# 单图编辑
prompt = f"Edit this image: {instruction}"
elif len(images) == 2:
# 双图合成
prompt = f"Combine these two images creatively: {instruction}"
else:
# 多图处理
prompt = f"Process these {len(images)} images together: {instruction}"
# 构建content
content = [{"type": "text", "text": prompt}]
for img in images:
content.append({
"type": "image_url",
"image_url": {"url": img}
})
# 发送请求...
return send_edit_request(content)
3. Base64 数据处理工具
import base64
import io
import re
from datetime import datetime
from PIL import Image
class Base64ImageHandler:
"""Base64图片处理工具类"""
@staticmethod
def extract_from_response(response_content):
"""从API响应中提取base64数据"""
patterns = [
r'data:image/([^;]+);base64,([A-Za-z0-9+/=]+)',
r'([A-Za-z0-9+/=]{100,})'
]
for pattern in patterns:
match = re.search(pattern, response_content)
if match:
if len(match.groups()) == 2:
return match.group(2), match.group(1) # data, format
else:
return match.group(1), 'png' # default to png
return None, None
@staticmethod
def save_to_file(base64_data, filename=None):
"""保存base64数据为文件"""
if not filename:
filename = f"image_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png"
image_data = base64.b64decode(base64_data)
with open(filename, 'wb') as f:
f.write(image_data)
return filename
@staticmethod
def to_pil_image(base64_data):
"""转换为PIL Image对象"""
image_data = base64.b64decode(base64_data)
return Image.open(io.BytesIO(image_data))
@staticmethod
def from_pil_image(pil_image, format='PNG'):
"""从PIL Image转换为base64"""
buffer = io.BytesIO()
pil_image.save(buffer, format=format)
img_str = base64.b64encode(buffer.getvalue()).decode()
return f"data:image/{format.lower()};base64,{img_str}"
⚠️ 注意事项
- 令牌类型:必须使用按次计费类型的令牌
- 调用端点:使用
/v1/chat/completions,不是/v1/images/edits - 返回格式:返回 base64 编码的编辑结果
🔍 常见问题
最多可以同时处理几张图片?
最多可以同时处理几张图片?
理论上没有硬性限制,但建议单次请求不超过 5 张图片以获得最佳性能。
编辑后的图片分辨率如何?
编辑后的图片分辨率如何?
系统会智能保持或优化分辨率,通常输出高质量图片,具体取决于输入图片和编辑需求。
与其他编辑API相比有什么优势?
与其他编辑API相比有什么优势?
主要优势包括:更低的价格、更快的处理速度、原生支持多图输入、优秀的中文理解能力。
🔗 相关资源
文生图 API
从文字描述生成图片
Nano Banana Pro 图改图
4K 高清、复杂多图编辑
API 密钥管理
创建和管理令牌
价格说明
查看详细价格表
🎨 专业提示:Nano Banana 编辑功能特别擅长理解复杂的编辑指令和创意要求,充分利用详细的描述可以获得更精准的编辑效果!