🧠 智能编辑新高度
Nano Banana Pro Edit 使用 Google Gemini 3 Pro 模型,具备极强的语义理解能力。它不仅是”修改图片”,而是”理解并重绘图片”。
控制台入口
创建 API Key,查看余额和调用日志
🚀 在线测试
影图 AI 即刻体验,无需写代码
前置要求
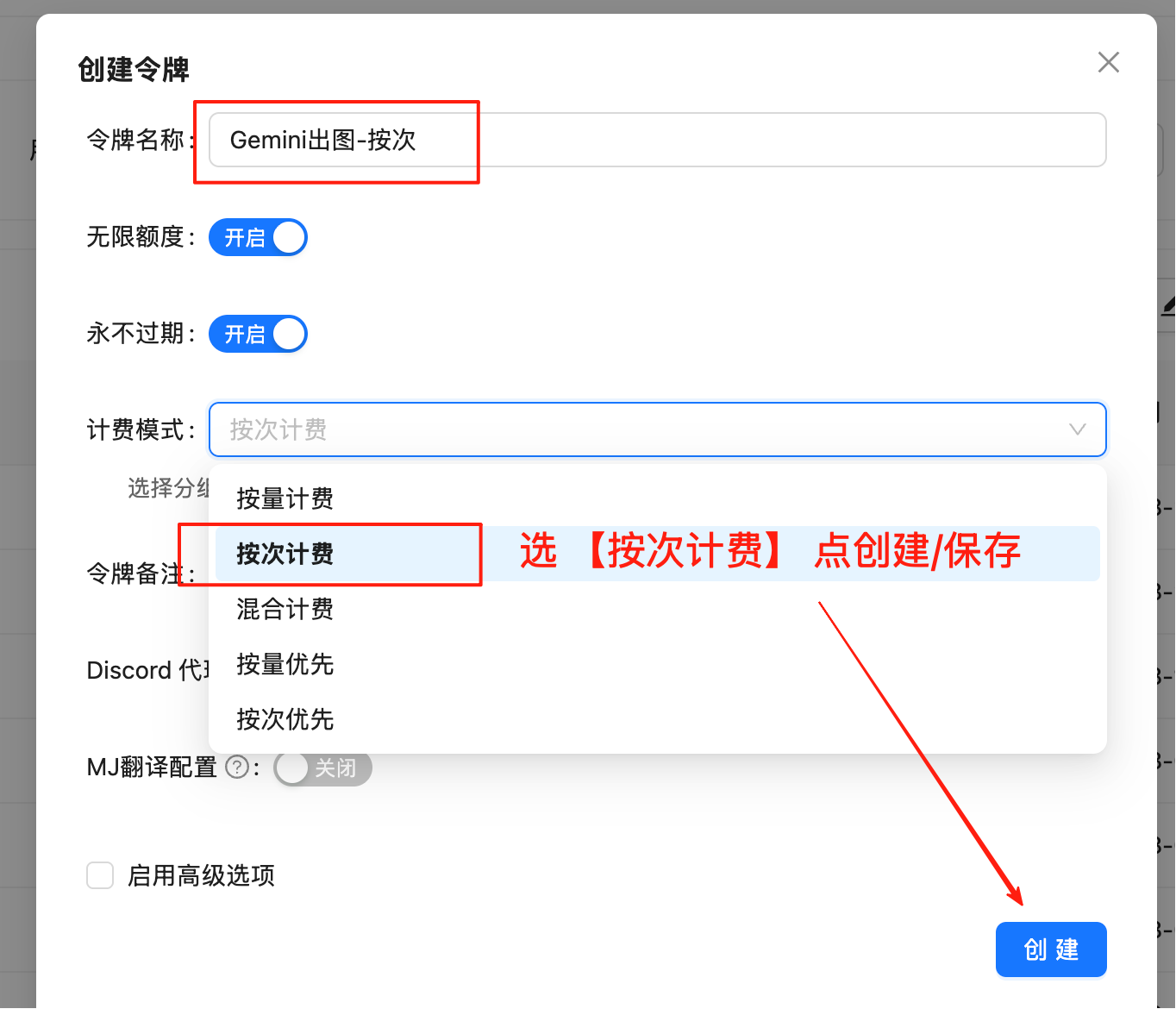
获取 API Key
登录 laozhang.ai 控制台 获取 API 密钥
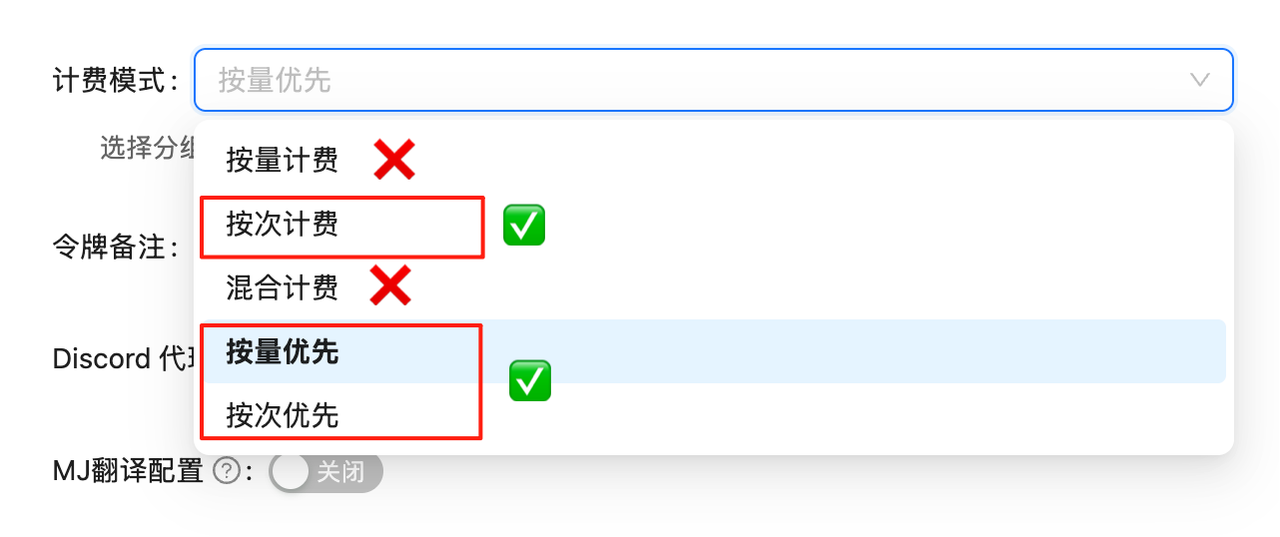
模型简介
Nano Banana Pro 编辑 (gemini-3-pro-image-preview) 专为需要精准控制和高质量输出的场景设计。不同于简单的滤镜或修补,它能理解复杂的自然语言指令,对画面进行逻辑性的修改。
核心能力
- 精准局部修改: “把那只猫换成一只戴眼镜的狗,但保持姿势不变”
- 风格完美迁移: “把这张照片变成赛博朋克风格的油画,光线要更加强烈”
- 多图创意融合: “结合这两张图,生成一张全新的海报”
- 4K 高清输出: 支持输出 2K/4K 分辨率的编辑结果
🌟 核心特性
- ⚡ 极速响应:平均 10 秒完成编辑
- 💰 价格以控制台为准:$0.09/次,实际扣费以控制台记录为准
- 🔄 双重兼容:支持 OpenAI SDK 和 Google 原生格式
- 📐 灵活尺寸:Google 原生格式支持 10 种纵横比
- 🖼️ 高分辨率:支持 1K、2K、4K 三种分辨率输出
- 🧠 思考模式:内置推理能力,理解复杂编辑指令
- 🌐 搜索接地:支持结合实时搜索数据进行编辑
- 🎨 多图参考:支持最多 14 张参考图片进行复杂合成
- 📦 Base64 输出:直接返回 base64 编码图片数据
- 🔗 URL 直传:Google 原生格式支持直接传入图片 URL(需海外可访问),无需 Base64 编码
🔀 两种调用方式
| 特性 | OpenAI 兼容模式 | Google 原生格式 |
|---|---|---|
| 端点 | /v1/chat/completions | /v1beta/models/gemini-3-pro-image-preview:generateContent |
| 输出尺寸 | 默认比例 | 支持 10 种纵横比 |
| 分辨率 | 固定 1K | 支持 1K/2K/4K |
| 多图支持 | ✅ 支持 | ✅ 支持(最多 14 张) |
| 兼容性 | 完美兼容 OpenAI SDK | 需要原生调用 |
| 返回格式 | Base64 | Base64 |
| 图片输入 | URL 或 Base64 | URL(fileData)或 Base64(inline_data) |
📋 模型对比
与其他编辑模型对比
| 模型 | 模型 ID | 计费方式 | 老张价格 | 外部参考价 | 节省 | 分辨率 | 速度 |
|---|---|---|---|---|---|---|---|
| Nano Banana Pro | gemini-3-pro-image-preview | 按次 | $0.09/次 | $0.24/次 | 62.5% | 1K/2K/4K | ~10秒 |
| Nano Banana2 | gemini-3.1-flash-image-preview | 按次 | $0.055/次 | - | - | 1K/2K/4K | ~10秒 |
| Nano Banana | gemini-2.5-flash-image | 按次 | $0.025/次 | $0.04/次 | 37.5% | 1K(固定) | ~10秒 |
| GPT-4o 编辑 | gpt-4o | Token | - | - | - | - | ~20秒 |
| DALL·E 2 编辑 | dall-e-2 | 按次 | - | $0.018/张 | - | 固定 | 较慢 |
Pro / Banana2 / Standard 详细对比
| 特性 | Nano Banana Pro | Nano Banana2 | Nano Banana |
|---|---|---|---|
| 模型 | gemini-3-pro-image-preview | gemini-3.1-flash-image-preview | gemini-2.5-flash-image |
| 技术基础 | Gemini 3 | Gemini 3.1 Flash | Gemini 2.5 |
| 分辨率 | 1K/2K/4K | 1K/2K/4K | 1K(固定) |
| 价格 | $0.09/次 | $0.055/次 | $0.025/次 |
| 思考模式 | ✅ 有 | ✅ 有 | ❌ 无 |
| 搜索接地 | ✅ 有 | ✅ 有 | ❌ 无 |
| 多图支持 | 最多 14 张 | 最多 14 张 | 最多 3 张 |
| 速度 | ~10秒 | ~10秒 | ~10秒 |
| 推荐场景 | 专业设计、复杂合成 | 日常高级用途、日常高级用途 | 快速修改、简单编辑 |
🚀 快速开始
准备工作
方式一:OpenAI 兼容模式
单图编辑 - Curl
单图编辑 - Python SDK
多图合成 - Python SDK
方式二:Google 原生格式(支持自定义纵横比 + 4K)
认证方式
Google 原生格式支持三种认证方式:支持的分辨率
| 纵横比 | 1K 分辨率 | 2K 分辨率 | 4K 分辨率 |
|---|---|---|---|
| 1:1 | 1024×1024 | 2048×2048 | 4096×4096 |
| 16:9 | 1376×768 | 2752×1536 | 5504×3072 |
| 9:16 | 768×1376 | 1536×2752 | 3072×5504 |
| 4:3 | 1200×896 | 2400×1792 | 4800×3584 |
| 3:4 | 896×1200 | 1792×2400 | 3584×4800 |
图片输入方式
Google 原生格式支持两种图片输入方式:4K 高清编辑 - Curl(Base64 方式)
4K 高清编辑 - Curl(URL 方式)
使用fileData.fileUri 直接传入在线图片 URL,无需转换为 Base64:
💡 URL 方式要点
- 使用
fileData.fileUri替代inline_data.data - 需要指定
mimeType(如image/png、image/jpeg) - 可选添加
role: "user"明确角色 - 图片 URL 必须是海外公网可直接访问的地址
Python 代码示例
💡 三个示例递进关系
示例1编辑图片 → 示例2用它变换风格 → 示例3融合前两张图。逻辑清晰!
示例 1:单图编辑 → 添加元素生成第一张图
示例 1:单图编辑 → 添加元素生成第一张图
示例 2:风格转换 → 用第一张图生成第二张图
示例 2:风格转换 → 用第一张图生成第二张图
示例 3:多图融合 → 用第一张和第二张生成第三张图
示例 3:多图融合 → 用第一张和第二张生成第三张图
示例 4:使用 URL 方式编辑在线图片
示例 4:使用 URL 方式编辑在线图片
完整 Python 工具脚本
完整 Python 工具脚本
🎯 编辑场景示例
1. 单图编辑 - 添加元素
2. 风格转换
3. 多图合成
💡 最佳实践
编辑指令优化
多图处理策略
❓ 常见问题
Pro 版和 Standard 版有什么区别?
Pro 版和 Standard 版有什么区别?
| 特性 | Nano Banana Pro | Nano Banana |
|---|---|---|
| 分辨率 | 1K/2K/4K | 1K(固定) |
| 思考模式 | ✅ 有 | ❌ 无 |
| 搜索接地 | ✅ 有 | ❌ 无 |
| 多图支持 | 最多 14 张 | 最多 3 张 |
| 价格 | $0.09/次 | $0.025/次 |
| 推荐场景 | 专业设计、复杂合成 | 快速修改、简单编辑 |
如何使用 4K 分辨率?
如何使用 4K 分辨率?
4K 仅 Nano Banana Pro 支持,使用 Google 原生格式并添加 重要:必须使用大写 “K”(1K、2K、4K)。
imageSize 参数:支持哪些图片格式?
支持哪些图片格式?
支持常见的图片格式:
- JPG/JPEG
- PNG
- WebP
- GIF(静态)
图片大小有限制吗?
图片大小有限制吗?
- 推荐大小:单张图片 ≤ 5MB
- 最大大小:≤ 10MB
- 过大的图片会增加处理时间,建议压缩后上传
可以同时处理多少张图片?
可以同时处理多少张图片?
- Nano Banana Pro:支持最多 14 张图片
- Nano Banana:支持最多 3 张图片
- 图片过多会影响生成质量和处理时间,建议 ≤ 4 张
为什么 Pro 版在老张 API 这么成本较低?
为什么 Pro 版在老张 API 这么成本较低?
| 模型 | 老张 API | 官网 | 节省 |
|---|---|---|---|
| Nano Banana Pro | $0.09/次 | $0.24/次 | 62.5% |
| Nano Banana | $0.025/次 | $0.04/次 | 37.5% |
支持中文编辑指令吗?
支持中文编辑指令吗?
完美支持! Gemini 3 Pro 拥有顶级的多语言理解能力,您可以直接使用中文描述编辑需求。
如何获取更好的编辑效果?
如何获取更好的编辑效果?
- 详细描述:提供具体的编辑细节
- 分步骤:复杂编辑分多个步骤描述
- 参考风格:指定艺术风格
- 保持主体:明确说明需要保留的内容
Google 原生格式支持哪些图片输入方式?
Google 原生格式支持哪些图片输入方式?
Google 原生格式支持两种图片输入方式:1. URL 方式(2. Base64 方式(⚠️ URL 方式限制:
fileData.fileUri) - 更简洁inline_data) - 更通用- 图片 URL 必须是海外公网可直接访问的地址
- 图片服务器不能有反爬机制(Cloudflare 验证、验证码等)
- 访问受限的图片,请使用 Base64 方式
- 图片托管在 AWS S3、Google Cloud Storage、Cloudinary 等 → 用 URL
- 图片位于受限网络或有访问限制 → 用 Base64
🎯 常见用例
- 电商换模特: 上传衣服图和模特图,生成穿搭效果
- 装修设计: 上传毛坯房照片,通过 Prompt 生成装修后效果
- 游戏素材: 快速修改游戏图标或角色外观
- 社交媒体: 将人像照片转换为各种艺术风格
- 产品展示: 将产品放入不同场景背景中
- 创意海报: 融合多张素材生成海报设计
🔗 相关资源
Pro 图像生成
学习如何使用 Nano Banana Pro 从文字生成图片
Standard 图像编辑
可选的 Nano Banana Standard 编辑版本
令牌管理
创建和管理你的 API 令牌
价格说明
查看详细的价格表和计费说明
📝 更新日志
2025-01:Google 原生格式支持 URL 图片输入
2025-01:Google 原生格式支持 URL 图片输入
🔗 新增 fileData.fileUri 方式
- 支持直接传入在线图片 URL,无需下载和 Base64 编码
- 新增 Curl 和 Python 代码示例
- 注意:图片 URL 需海外公网可访问且无反爬机制
- 新增相关 FAQ 说明
2025-01:Nano Banana Pro 编辑独立文档上线
2025-01:Nano Banana Pro 编辑独立文档上线
🚀 Nano Banana Pro 编辑专属页面
- 从混合文档拆分为独立的 Pro 版本文档
- 完整的 4K 分辨率编辑指南
- 详细的多图合成说明
- 完整的代码示例和最佳实践
- 与 Nano Banana Standard 的对比说明