该页面属于 Sora2 旧线路文档,目前已过时,仅供历史排查参考。当前可用入口请使用 Sora 官方 API 转发方案。
Python 完整示例
基础文生视频
import openai
import time
# 初始化客户端
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api2.laozhang.ai/v1"
)
def generate_video(prompt, model="sora_video2"):
"""生成视频"""
try:
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
)
return response.choices[0].message.content
except Exception as e:
print(f"错误:{e}")
return None
# 使用示例
prompt = "一只可爱的猫咪在阳光明媚的花园里玩球"
result = generate_video(prompt)
print(result)
流式输出示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api2.laozhang.ai/v1"
)
def generate_video_stream(prompt, model="sora_video2"):
"""流式生成视频,实时显示进度"""
stream = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
],
stream=True
)
video_url = None
for chunk in stream:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end='', flush=True)
# 提取视频链接
if "https://" in content and ".mp4" in content:
import re
match = re.search(r'https://[^\s\)]+\.mp4', content)
if match:
video_url = match.group(0)
print("\n")
return video_url
# 使用示例
prompt = "一只可爱的猫咪在阳光明媚的花园里玩球"
video_url = generate_video_stream(prompt)
print(f"\n视频链接:{video_url}")
图生视频(URL)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api2.laozhang.ai/v1"
)
def generate_video_from_image(prompt, image_url, model="sora_video2"):
"""从图片生成视频"""
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {
"url": image_url
}
}
]
}
]
)
return response.choices[0].message.content
# 使用示例
prompt = "生成视频:让这个手办形象从桌子上跳出来,变成活人的一个场景~"
image_url = "https://filesystem.site/cdn/download/20250407/OhFd8JofOAJCsNOCsM1Y794qnkNO3L.png"
result = generate_video_from_image(prompt, image_url)
print(result)
图生视频(Base64)
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api2.laozhang.ai/v1"
)
def encode_image(image_path):
"""将本地图片编码为 base64"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def generate_video_from_local_image(prompt, image_path, model="sora_video2"):
"""从本地图片生成视频"""
# 编码图片
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
}
]
}
]
)
return response.choices[0].message.content
# 使用示例
prompt = "让这个场景动起来,加入更多动态元素"
image_path = "/path/to/your/image.png"
result = generate_video_from_local_image(prompt, image_path)
print(result)
自动下载视频
import openai
import re
import requests
import os
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api2.laozhang.ai/v1"
)
def extract_video_url(content):
"""从响应中提取视频链接"""
match = re.search(r'https://[^\s\)]+\.mp4', content)
return match.group(0) if match else None
def download_video(url, save_path):
"""下载视频到本地"""
try:
response = requests.get(url, stream=True)
response.raise_for_status()
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"视频已保存到:{save_path}")
return True
except Exception as e:
print(f"下载失败:{e}")
return False
def generate_and_download(prompt, save_dir="./videos", model="sora_video2"):
"""生成视频并自动下载"""
# 创建保存目录
os.makedirs(save_dir, exist_ok=True)
# 生成视频
print("正在生成视频...")
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
)
content = response.choices[0].message.content
print(content)
# 提取视频链接
video_url = extract_video_url(content)
if not video_url:
print("未找到视频链接")
return None
# 下载视频
import time
filename = f"sora_{int(time.time())}.mp4"
save_path = os.path.join(save_dir, filename)
if download_video(video_url, save_path):
return save_path
return None
# 使用示例
prompt = "一只可爱的猫咪在阳光明媚的花园里玩球"
video_path = generate_and_download(prompt)
print(f"视频路径:{video_path}")
JavaScript/Node.js 示例
基础文生视频
const OpenAI = require('openai');
const client = new OpenAI({
apiKey: 'YOUR_API_KEY',
baseURL: 'https://api2.laozhang.ai/v1'
});
async function generateVideo(prompt, model = 'sora_video2') {
try {
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: 'user',
content: [
{
type: 'text',
text: prompt
}
]
}
]
});
return response.choices[0].message.content;
} catch (error) {
console.error('错误:', error);
return null;
}
}
// 使用示例
generateVideo('一只可爱的猫咪在阳光明媚的花园里玩球')
.then(result => console.log(result));
流式输出
const OpenAI = require('openai');
const client = new OpenAI({
apiKey: 'YOUR_API_KEY',
baseURL: 'https://api2.laozhang.ai/v1'
});
async function generateVideoStream(prompt, model = 'sora_video2') {
const stream = await client.chat.completions.create({
model: model,
messages: [
{
role: 'user',
content: [
{
type: 'text',
text: prompt
}
]
}
],
stream: true
});
let videoUrl = null;
for await (const chunk of stream) {
const content = chunk.choices[0]?.delta?.content;
if (content) {
process.stdout.write(content);
// 提取视频链接
const match = content.match(/https:\/\/[^\s\)]+\.mp4/);
if (match) {
videoUrl = match[0];
}
}
}
console.log('\n');
return videoUrl;
}
// 使用示例
generateVideoStream('一只可爱的猫咪在阳光明媚的花园里玩球')
.then(url => console.log(`\n视频链接:${url}`));
自动下载视频
const OpenAI = require('openai');
const fs = require('fs');
const https = require('https');
const path = require('path');
const client = new OpenAI({
apiKey: 'YOUR_API_KEY',
baseURL: 'https://api2.laozhang.ai/v1'
});
function downloadVideo(url, savePath) {
return new Promise((resolve, reject) => {
const file = fs.createWriteStream(savePath);
https.get(url, (response) => {
response.pipe(file);
file.on('finish', () => {
file.close();
console.log(`视频已保存到:${savePath}`);
resolve(savePath);
});
}).on('error', (err) => {
fs.unlink(savePath, () => {});
console.error(`下载失败:${err.message}`);
reject(err);
});
});
}
async function generateAndDownload(prompt, saveDir = './videos', model = 'sora_video2') {
// 创建保存目录
if (!fs.existsSync(saveDir)) {
fs.mkdirSync(saveDir, { recursive: true });
}
// 生成视频
console.log('正在生成视频...');
const response = await client.chat.completions.create({
model: model,
messages: [
{
role: 'user',
content: [
{
type: 'text',
text: prompt
}
]
}
]
});
const content = response.choices[0].message.content;
console.log(content);
// 提取视频链接
const match = content.match(/https:\/\/[^\s\)]+\.mp4/);
if (!match) {
console.log('未找到视频链接');
return null;
}
const videoUrl = match[0];
const filename = `sora_${Date.now()}.mp4`;
const savePath = path.join(saveDir, filename);
// 下载视频
await downloadVideo(videoUrl, savePath);
return savePath;
}
// 使用示例
generateAndDownload('一只可爱的猫咪在阳光明媚的花园里玩球')
.then(path => console.log(`视频路径:${path}`));
Cherry Studio 使用场景
Cherry Studio 是一款强大的 AI 对话客户端,支持 Sora 2 视频生成。配置步骤
1
配置 API
在 Cherry Studio 中添加 laozhang.ai 的 API 配置详见:Cherry Studio 配置文档
2
启用视频功能
在模型设置中找到 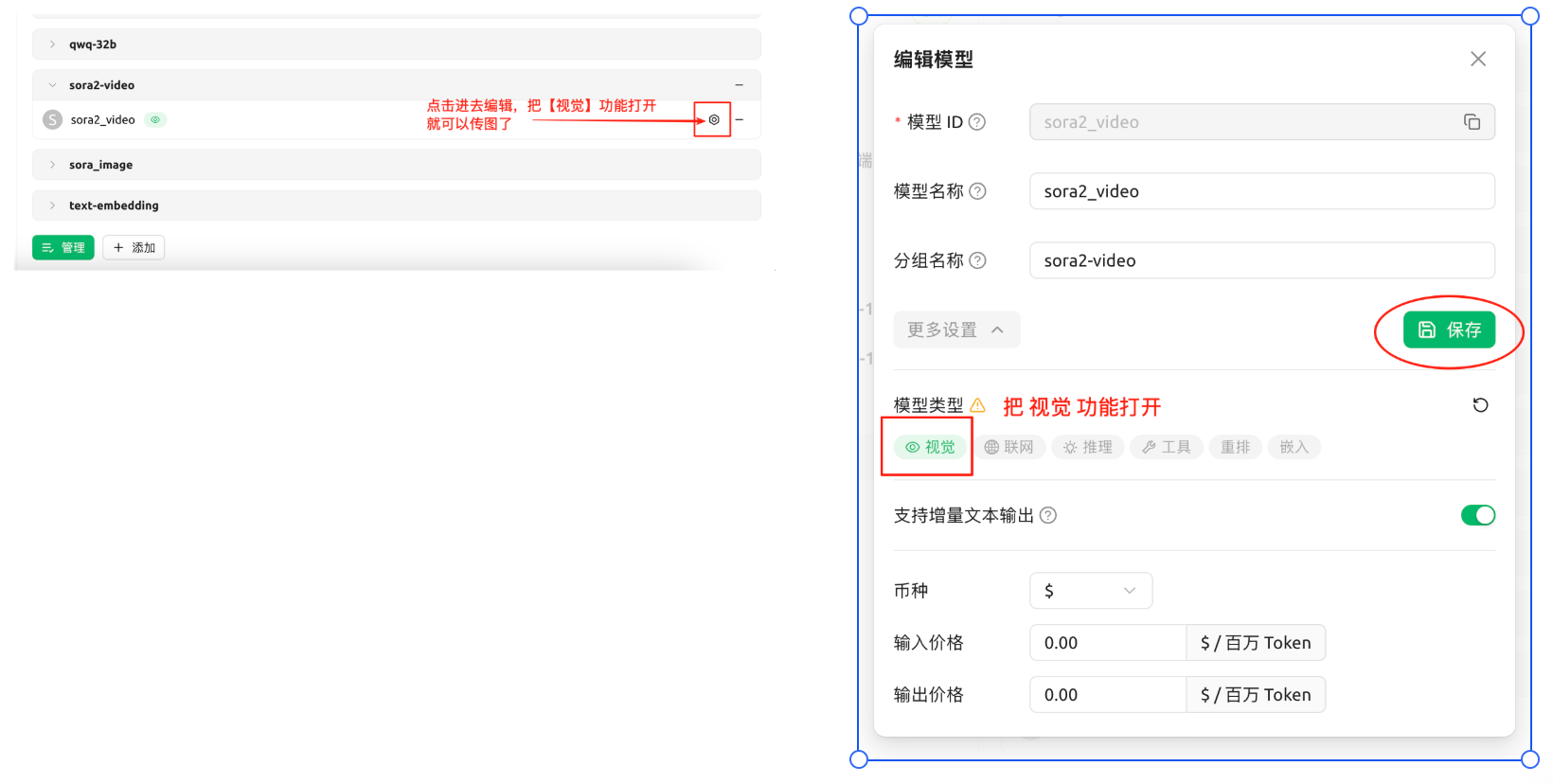
sora_video2,打开视频生成功能3
文生视频
直接输入文字描述即可生成视频
4
图生视频
上传图片 + 提示词生成视频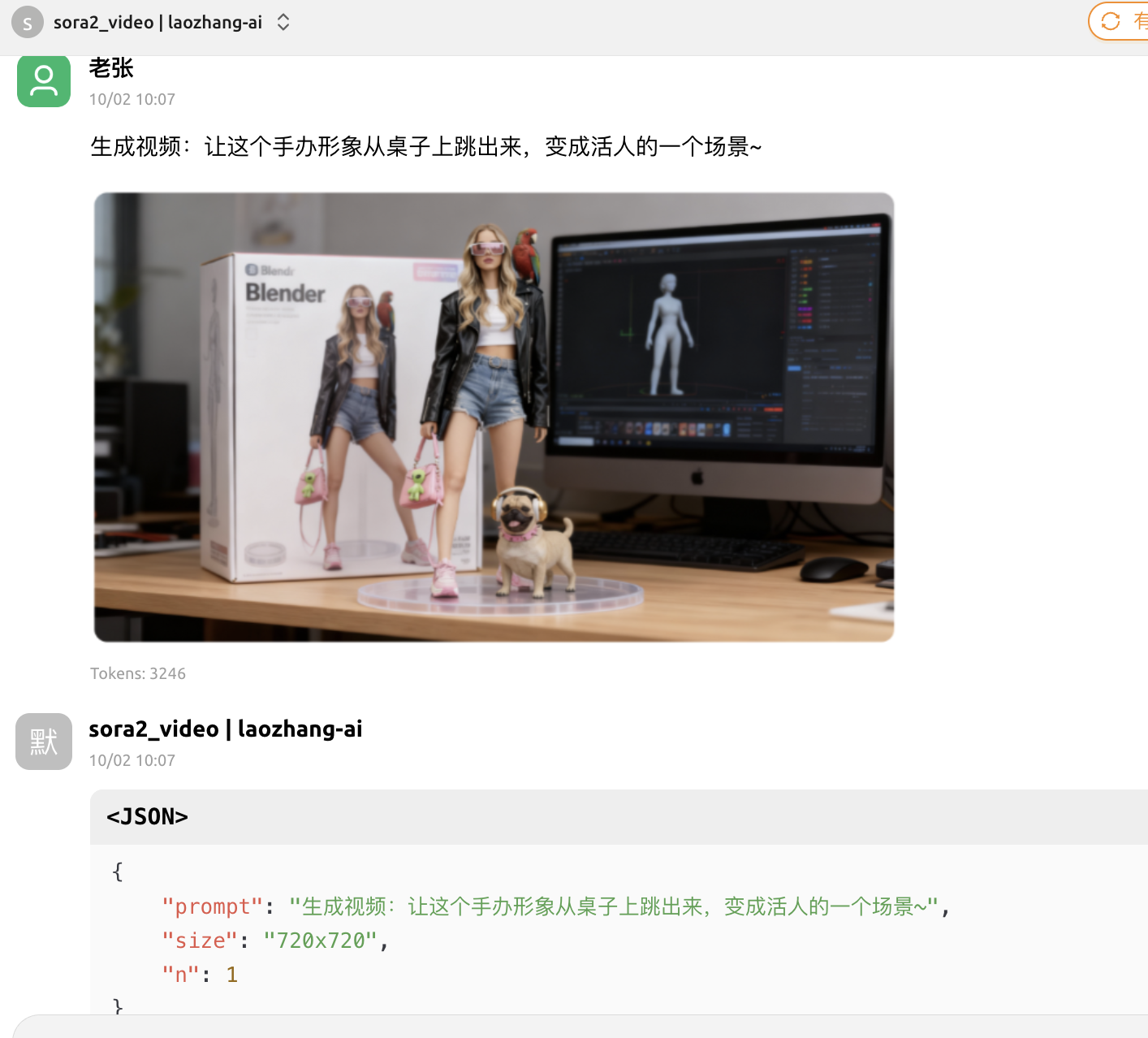
使用示例
文生视频
在 Cherry Studio 对话框中直接输入:一只可爱的橘猫在阳光下打瞌睡,突然被一只蝴蝶惊醒,开始追逐蝴蝶
- 显示提示词优化结果
- 展示生成进度(队列状态、百分比)
- 提供视频播放链接
图生视频
- 点击上传图片按钮,选择参考图片
- 输入提示词:
生成视频:让这个场景动起来,加入微风吹过、树叶摇曳的效果
批量生成示例
Python 批量生成
import openai
import time
import concurrent.futures
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api2.laozhang.ai/v1"
)
def generate_single_video(prompt, model="sora_video2"):
"""生成单个视频"""
try:
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
)
return {
"prompt": prompt,
"result": response.choices[0].message.content,
"success": True
}
except Exception as e:
return {
"prompt": prompt,
"error": str(e),
"success": False
}
def batch_generate(prompts, max_workers=3, model="sora_video2"):
"""批量生成视频"""
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [
executor.submit(generate_single_video, prompt, model)
for prompt in prompts
]
for future in concurrent.futures.as_completed(futures):
result = future.result()
results.append(result)
if result['success']:
print(f"✓ 成功:{result['prompt'][:30]}...")
else:
print(f"✗ 失败:{result['prompt'][:30]}... - {result['error']}")
return results
# 使用示例
prompts = [
"一只猫咪在花园里玩球",
"日落时分的海滩,海浪轻拍沙滩",
"繁忙的城市街道,车水马龙",
"森林中的小溪,阳光透过树叶洒下",
]
results = batch_generate(prompts, max_workers=2)
# 统计结果
success_count = sum(1 for r in results if r['success'])
print(f"\n生成完成:成功 {success_count}/{len(prompts)}")
最佳实践
提示词优化
提示词优化
- 描述具体场景和动作
- 包含光线、氛围等细节
- 使用
@sama等授权真人ID - 避免描述真实人脸(会被拒绝)
错误处理
错误处理
- 设置合理的超时时间(建议 5 分钟)
- 添加重试逻辑
- 记录失败原因
- 使用流式输出监控进度
视频下载
视频下载
- 生成后立即下载(有效期 1 天)
- 使用流式下载大文件
- 保存到本地或云存储
- 做好备份
成本优化
成本优化
- 两个模型稳定性都极高
- 批量生成时控制并发数
- 失败计费以控制台记录为准,可放心重试
- 及时下载视频(存储时效 1 天)
下一步
常见问题
查看常见问题解答
模型定价
了解详细的模型对比
API 参考
查看完整的 API 文档
快速开始
回到快速开始指南